
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 웨어하우스 보관 최적화
- 코딩테스트
- Inventory Optimization
- tensorflow
- TensorFlowGPU
- MS SQL Server
- 피그마인디언
- Labor Management System
- Product Demand
- 파이썬
- SKU Consolidation
- ProfileReport
- HackerRank
- oracle
- eda
- ModelCheckPoint
- leetcode
- 프로그래머스
- 코딩테스트연습
- 딥러닝
- MySQL
- SQL
- Gaimification
- pandas profiling
- forecast
- ABC Analysis
- 신경쓰기의 기술
- 당신의 인생이 왜 힘들지 않아야 한다고 생각하십니까
- 데이터분석
- kaggle
Archives
- Today
- Total
오늘도 배운다
탐색적 데이터분석 쉽게하기 - Pandas -profiling 본문
목표
Pandas-profiling을 이용하여 데이터셋의 구성에 대한 자세한 정보를 쉽게 얻기
라이브러리 설치
pip install -U pandas-profiling
사용한 데이터셋 - E-Commerce Shipping Data from Kaggle
데이터셋 정보를 html 파일로 추출하기
# 필요한 라이브러리, 클래스 임포트
import pandas as pd
from pandas_profiling import ProfileReport
# 데이터 불러오기
df = pd.read_csv('./archive/Train.csv')
# 데이터셋 정보 html 파일로 저장하기
pf = ProfileReport(df, explorative=True)
pf.to_file('eCommerce_shipping_dataset.html')
요약
레포트는 다음으로 구성됨
a. 개요
b. 변수
c. 변수 간 상호작용 관계
d. 상관관계
e. 결측치
f. 샘플
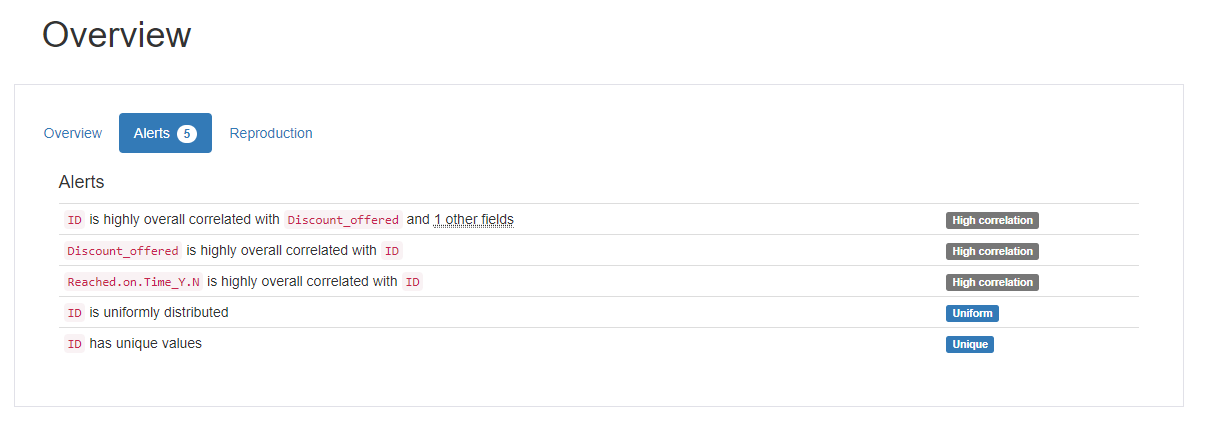
1. 개요(Overview)
데이터셋과 관련된 정보


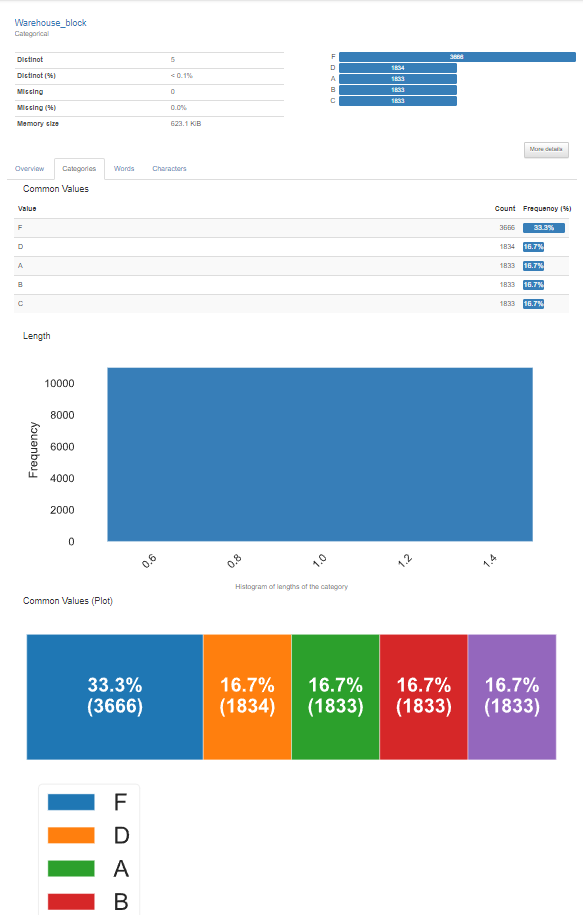
2. Variables
각 변수의 고유값 개수, 결측치 수, 평균 등에 대한 정보를 보여줌

'More details' 버튼을 눌러 더욱 자세한 내용이 확인가능하다

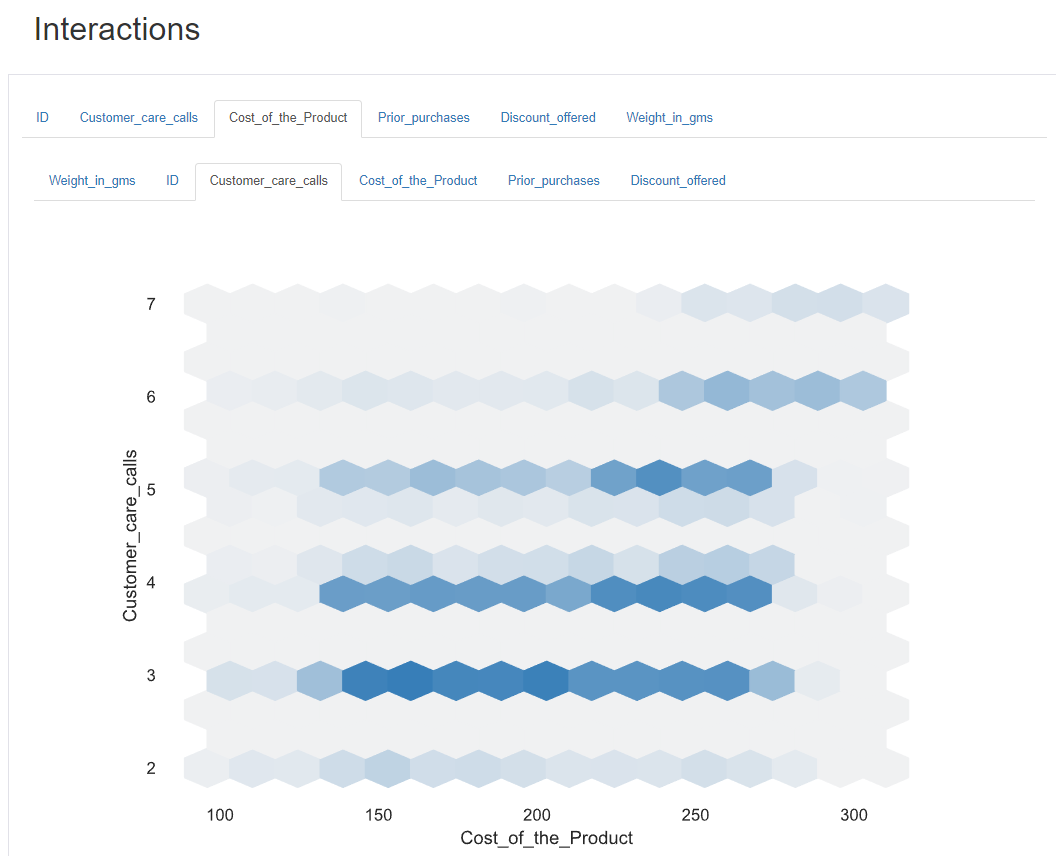
3. Interactions
변수간 관계를 시각화로 볼 수 있다
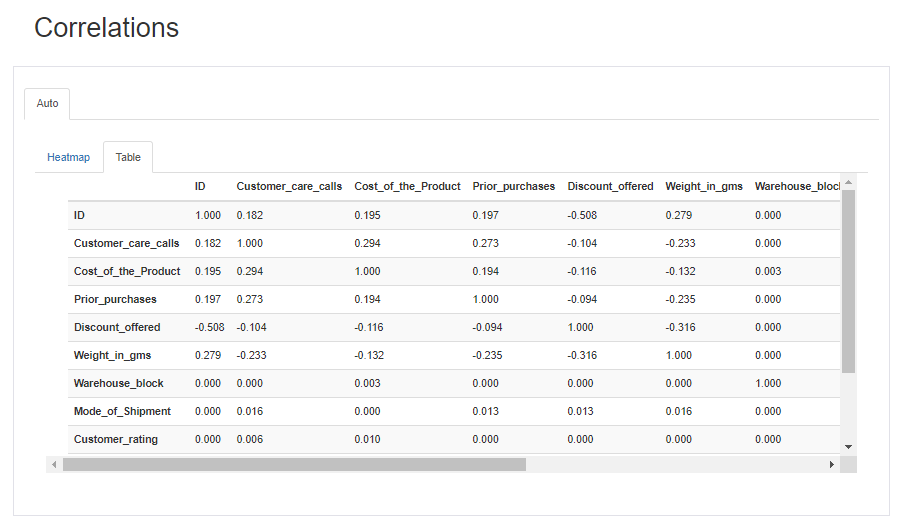
4. Correlations

5. Missing Values
결측치에 대한 정보도 주어진다
더이상 missingno를 사용할 일이 없을듯하다

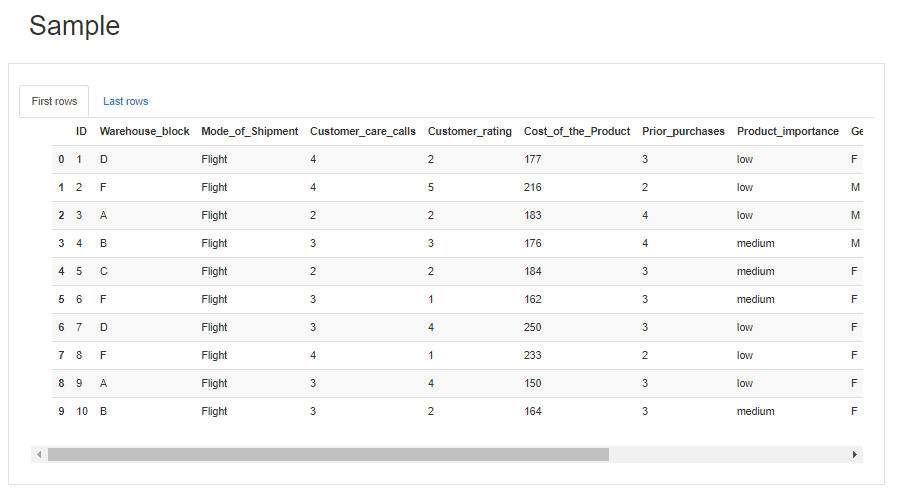
6. 샘플
pandas의 head, tail 기능과 같다
결론
pandas_profiling 을 이용하여
탐색적 데이터분석 (EDA) 시간을
상당하게 줄일 수 있다.
eCommerce Shipping data 분석에 활용해보기.
참고자료
728x90
'빅데이터(파이썬)' 카테고리의 다른 글
| Pandas read_csv가 너무 느리다면? 대용량 csv 파일 빠르게 불러오기 (0) | 2022.11.17 |
|---|
'빅데이터(파이썬)' Related Articles
more

Comments